Series
Introduction to working with PhenoCam Images
Phenology—the study of how nature changes seasonally—is a core focus of research enabled by NEON data and infrastructure. NEON gathers phenological data at its field sites through various methods including field sampling of specific plants and insects, flyovers to collect remote sensing data and in situ phenocams that collect phenology image data. These data are hosted by and also accessible via the as NEON Data Products DP1.00033.001, DP1.00042.001, and DP1.20002.001.
The tutorials in this series were developed in close collaboration with .
This series provides instruction on how to work with the photographs from the PhenoCam Network to extract the day you want for phenology or time-series analyses.
Learning Objectives
After completing the series, you will be able to:
- Access and download raw and processed data from the PhenoCam network
- Extract time-series data from any stack of digital images, including but not limited to the images of the PhenoCam network
- Quantitatively remove data obtained from bad weather conditions (such as presence fog and cloud, camera field of view shifts)
- Analyze the extracted time-series to address environmental questions
Things You’ll Need To Complete This Series
Install R & Set up RStudio
To complete the tutorial series, you will need an updated version of R (version 3.4 or later) and, preferably, RStudio installed on your computer.
is a programming language that specializes in statistical computing. It is a
powerful tool for exploratory data analysis. To interact with R, we strongly
recommend
,
an interactive development environment (IDE).
Install R Packages
You can chose to install packages with each lesson or you can download all of the necessary R packages now. You can install the necessary R packages by running the code below
install.packages('rgdal')
utils::install.packages('devtools', repos = "http://cran.us.r-project.org" )
install.packages('hazer')
install.packages('jpeg')
install.packages('lubridate')
install.packages('hazer')
install.packages('data.table')
install.packages('phenocamapi')
install.packages('phenocamr')
install.packages('xROI')
devtools::install_github('khufkens/phenor')
install.packages('daymetr')
install.packages('tidyverse')
install.packages('shiny')
install.packages('xaringan')
install.packages('maps')
install.packages('raster')
install.packages('sp')
More on Packages in R � Adapted from Software Carpentry.
Interacting with the PhenoCam Server using phenocamapi R Package
Last Updated: Apr 10, 2025
The is developed to simplify interacting with the dataset and perform data wrangling steps on PhenoCam sites' data and metadata.
This tutorial will show you the basic commands for accessing PhenoCam data through the PhenoCam API. The phenocampapi R package is developed and maintained by the PhenoCam team. The most recent release is available on GitHub (). can be found on how to merge external time-series (e.g. Flux data) with the PhenoCam time-series.
We begin with several useful skills and tools for extracting PhenoCam data directly from the server:
- Exploring the PhenoCam metadata
- Filtering the dataset by site attributes
- Downloading PhenoCam time-series data
- Extracting the list of midday images
- Downloading midday images for a given time range
Exploring PhenoCam metadata
Each PhenoCam site has specific metadata including but not limited to how a site is set up and where it is located, what vegetation type is visible from the camera, and its meteorological regime. Each PhenoCam may have zero to several Regions of Interest (ROIs) per vegetation type. The phenocamapi package is an interface to interact with the PhenoCam server to extract those data and process them in an R environment.
To explore the PhenoCam data, we'll use several packages for this tutorial.
library(data.table) #installs package that creates a data frame for visualizing data in row-column table format
library(phenocamapi) #installs packages of time series and phenocam data from the Phenology Network. Loads required packages rjson, bitops and RCurl
library(lubridate) #install time series data package
library(jpeg)
We can obtain an up-to-date data.frame of the metadata of the entire PhenoCam
network using the get_phenos() function. The returning value would be a
data.table in order to simplify further data exploration.
#Obtain phenocam metadata from the Phenology Network in form of a data.table
phenos <- get_phenos()
#Explore metadata table
head(phenos$site) #preview first six rows of the table. These are the first six phenocam sites in the Phenology Network
#> [1] "aafcottawacfiaf14e" "aafcottawacfiaf14n" "aafcottawacfiaf14w" "acadia"
#> [5] "admixpasture" "adrycpasture"
colnames(phenos) #view all column names.
#> [1] "site" "lat" "lon"
#> [4] "elev" "active" "utc_offset"
#> [7] "date_first" "date_last" "infrared"
#> [10] "contact1" "contact2" "site_description"
#> [13] "site_type" "group" "camera_description"
#> [16] "camera_orientation" "flux_data" "flux_networks"
#> [19] "flux_sitenames" "dominant_species" "primary_veg_type"
#> [22] "secondary_veg_type" "site_meteorology" "MAT_site"
#> [25] "MAP_site" "MAT_daymet" "MAP_daymet"
#> [28] "MAT_worldclim" "MAP_worldclim" "koeppen_geiger"
#> [31] "ecoregion" "landcover_igbp" "dataset_version1"
#> [34] "site_acknowledgements" "modified" "flux_networks_name"
#> [37] "flux_networks_url" "flux_networks_description"
#This is all the metadata we have for the phenocams in the Phenology Network
Now we have a better idea of the types of metadata that are available for the Phenocams.
Remove null values
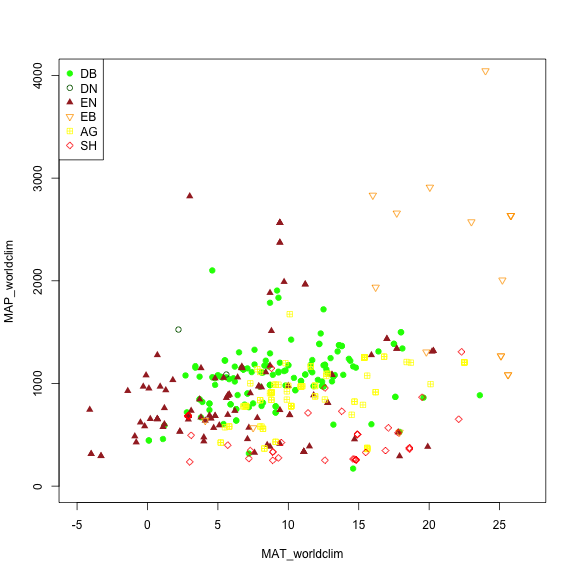
We may want to explore some of the patterns in the metadata before we jump into specific locations. Let's look at Mean Annual Precipitation (MAP) and Mean Annual Temperature (MAT) across the different field site and classify those by the primary vegetation type ('primary_veg_type') for each site.
| Abbreviation | Description | |----------|:-------------:|------:| | AG | agriculture | | DB | deciduous broadleaf | | DN | deciduous needleleaf | | EB | evergreen broadleaf | | EN | evergreen needleleaf | | GR | grassland | | MX | mixed vegetation (generally EN/DN, DB/EN, or DB/EB) | | SH | shrubs | | TN | tundra (includes sedges, lichens, mosses, etc.) | | WT | wetland | | NV | non-vegetated | | RF | reference panel | | XX | unspecified |
To do this we'd first want to remove the sites where there is not data and then plot the data.
# #Some sites do not have data on Mean Annual Precipitation (MAP) and Mean Annual Temperature (MAT).
# removing the sites with unknown MAT and MAP values
phenos <- phenos[!((MAT_worldclim == -9999)|(MAP_worldclim == -9999))]
# Making a plot showing all sites by their vegetation type (represented as different symbols and colors) plotting across meteorology (MAT and MAP) space. Refer to table to identify vegetation type acronyms.
phenos[primary_veg_type=='DB', plot(MAT_worldclim, MAP_worldclim, pch = 19, col = 'green', xlim = c(-5, 27), ylim = c(0, 4000))]
#> NULL
phenos[primary_veg_type=='DN', points(MAT_worldclim, MAP_worldclim, pch = 1, col = 'darkgreen')]
#> NULL
phenos[primary_veg_type=='EN', points(MAT_worldclim, MAP_worldclim, pch = 17, col = 'brown')]
#> NULL
phenos[primary_veg_type=='EB', points(MAT_worldclim, MAP_worldclim, pch = 25, col = 'orange')]
#> NULL
phenos[primary_veg_type=='AG', points(MAT_worldclim, MAP_worldclim, pch = 12, col = 'yellow')]
#> NULL
phenos[primary_veg_type=='SH', points(MAT_worldclim, MAP_worldclim, pch = 23, col = 'red')]
#> NULL
legend('topleft', legend = c('DB','DN', 'EN','EB','AG', 'SH'),
pch = c(19, 1, 17, 25, 12, 23),
col = c('green', 'darkgreen', 'brown', 'orange', 'yellow', 'red' ))
Filtering using attributes
Alternatively, we may want to only include Phenocams with certain attributes in
our datasets. For example, we may be interested only in sites with a co-located
flux tower. For this, we'd want to filter for those with a flux tower using the
flux_sitenames attribute in the metadata.
# Create a data table only including the sites that have flux_data available and where the FLUX site name is specified
phenofluxsites <- phenos[flux_data==TRUE&!is.na(flux_sitenames)&flux_sitenames!='',
.(PhenoCam=site, Flux=flux_sitenames)] # return as table
#Specify to retain variables of Phenocam site and their flux tower name
phenofluxsites <- phenofluxsites[Flux!='']
# view the first few rows of the data table
head(phenofluxsites)
#> PhenoCam Flux
#> <char> <char>
#> 1: admixpasture NZ-ADw
#> 2: alercecosteroforest CL-ACF
#> 3: alligatorriver US-NC4
#> 4: amtsvenn No
#> 5: arkansaswhitaker US-RGW
#> 6: arsbrooks10 US-Br1: Brooks Field Site 10- Ames
We could further identify which of those Phenocams with a flux tower and in
deciduous broadleaf forests (primary_veg_type=='DB').
#list deciduous broadleaf sites with a flux tower
DB.flux <- phenos[flux_data==TRUE&primary_veg_type=='DB',
site] # return just the site names as a list
# see the first few rows
head(DB.flux)
#> [1] "alligatorriver" "bartlett" "bartlettir" "bbc1" "bbc2"
#> [6] "bbc3"
PhenoCam time series
PhenoCam time series are extracted time series data obtained from regions of interest (ROI's) for a given site.
Obtain ROIs
To download the phenological time series from the PhenoCam, we need to know the
site name, vegetation type and ROI ID. This information can be obtained from each
specific PhenoCam page on the
or by using the get_rois() function.
# Obtaining the list of all the available regions of interest (ROI's) on the PhenoCam server and producing a data table
rois <- get_rois()
# view the data variables in the data table
colnames(rois)
#> [1] "roi_name" "site" "lat" "lon"
#> [5] "roitype" "active" "show_link" "show_data_link"
#> [9] "sequence_number" "description" "first_date" "last_date"
#> [13] "site_years" "missing_data_pct" "roi_page" "roi_stats_file"
#> [17] "one_day_summary" "three_day_summary" "data_release"
# view first few regions of of interest (ROI) locations
head(rois$roi_name)
#> [1] "aafcottawacfiaf14n_AG_1000" "admixpasture_AG_1000" "adrycpasture_AG_1000"
#> [4] "alercecosteroforest_EN_1000" "alligatorriver_DB_1000" "almondifapa_AG_1000"
Download time series
The get_pheno_ts() function can download a time series and return the result
as a data.table.
Let's work with the
and specifically the ROI
we can run the following code.
# list ROIs for dukehw
rois[site=='dukehw',]
#> roi_name site lat lon roitype active show_link show_data_link
#> <char> <char> <num> <num> <char> <lgcl> <lgcl> <lgcl>
#> 1: dukehw_DB_1000 dukehw 35.97358 -79.10037 DB TRUE TRUE TRUE
#> sequence_number description first_date last_date site_years
#> <num> <char> <char> <char> <char>
#> 1: 1000 canopy level DB forest at awesome Duke forest 2013-06-01 2024-12-30 10.7
#> missing_data_pct roi_page
#> <char> <char>
#> 1: 8.0 https://phenocam.nau.edu/webcam/roi/dukehw/DB_1000/
#> roi_stats_file
#> <char>
#> 1: https://phenocam.nau.edu/data/archive/dukehw/ROI/dukehw_DB_1000_roistats.csv
#> one_day_summary
#> <char>
#> 1: https://phenocam.nau.edu/data/archive/dukehw/ROI/dukehw_DB_1000_1day.csv
#> three_day_summary data_release
#> <char> <lgcl>
#> 1: https://phenocam.nau.edu/data/archive/dukehw/ROI/dukehw_DB_1000_3day.csv NA
# Obtain the decidous broadleaf, ROI ID 1000 data from the dukehw phenocam
dukehw_DB_1000 <- get_pheno_ts(site = 'dukehw', vegType = 'DB', roiID = 1000, type = '3day')
# Produces a list of the dukehw data variables
str(dukehw_DB_1000)
#> Classes 'data.table' and 'data.frame': 1414 obs. of 35 variables:
#> $ date : chr "2013-06-01" "2013-06-04" "2013-06-07" "2013-06-10" ...
#> $ year : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
#> $ doy : int 152 155 158 161 164 167 170 173 176 179 ...
#> $ image_count : int 57 76 77 77 77 78 21 0 0 0 ...
#> $ midday_filename : chr "dukehw_2013_06_01_120111.jpg" "dukehw_2013_06_04_120119.jpg" "dukehw_2013_06_07_120112.jpg" "dukehw_2013_06_10_120108.jpg" ...
#> $ midday_r : num 91.3 76.4 60.6 76.5 88.9 ...
#> $ midday_g : num 97.9 85 73.2 82.2 95.7 ...
#> $ midday_b : num 47.4 33.6 35.6 37.1 51.4 ...
#> $ midday_gcc : num 0.414 0.436 0.432 0.42 0.406 ...
#> $ midday_rcc : num 0.386 0.392 0.358 0.391 0.377 ...
#> $ r_mean : num 87.6 79.9 72.7 80.9 83.8 ...
#> $ r_std : num 5.9 6 9.5 8.23 5.89 ...
#> $ g_mean : num 92.1 86.9 84 88 89.7 ...
#> $ g_std : num 6.34 5.26 7.71 7.77 6.47 ...
#> $ b_mean : num 46.1 38 39.6 43.1 46.7 ...
#> $ b_std : num 4.48 3.42 5.29 4.73 4.01 ...
#> $ gcc_mean : num 0.408 0.425 0.429 0.415 0.407 ...
#> $ gcc_std : num 0.00859 0.0089 0.01318 0.01243 0.01072 ...
#> $ gcc_50 : num 0.408 0.427 0.431 0.416 0.407 ...
#> $ gcc_75 : num 0.414 0.431 0.435 0.424 0.415 ...
#> $ gcc_90 : num 0.417 0.434 0.44 0.428 0.421 ...
#> $ rcc_mean : num 0.388 0.39 0.37 0.381 0.38 ...
#> $ rcc_std : num 0.01176 0.01032 0.01326 0.00881 0.00995 ...
#> $ rcc_50 : num 0.387 0.391 0.373 0.383 0.382 ...
#> $ rcc_75 : num 0.391 0.396 0.378 0.388 0.385 ...
#> $ rcc_90 : num 0.397 0.399 0.382 0.391 0.389 ...
#> $ max_solar_elev : num 76 76.3 76.6 76.8 76.9 ...
#> $ snow_flag : logi NA NA NA NA NA NA ...
#> $ outlierflag_gcc_mean: logi NA NA NA NA NA NA ...
#> $ outlierflag_gcc_50 : logi NA NA NA NA NA NA ...
#> $ outlierflag_gcc_75 : logi NA NA NA NA NA NA ...
#> $ outlierflag_gcc_90 : logi NA NA NA NA NA NA ...
#> $ YEAR : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
#> $ DOY : int 152 155 158 161 164 167 170 173 176 179 ...
#> $ YYYYMMDD : chr "2013-06-01" "2013-06-04" "2013-06-07" "2013-06-10" ...
#> - attr(*, ".internal.selfref")=<externalptr>
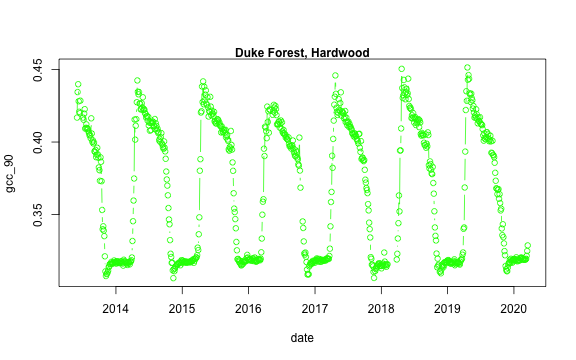
We now have a variety of data related to this ROI from the Hardwood Stand at Duke Forest.
Green Chromatic Coordinate (GCC) is a measure of "greenness" of an area and is
widely used in Phenocam images as an indicator of the green pigment in vegetation.
Let's use this measure to look at changes in GCC over time at this site. Looking
back at the available data, we have several options for GCC. gcc90 is the 90th
quantile of GCC in the pixels across the ROI (for more details,
).
We'll use this as it tracks the upper greenness values while not including many
outliners.
Before we can plot gcc-90 we do need to fix our dates and convert them from
Factors to Date to correctly plot.
# Convert date variable into date format
dukehw_DB_1000[,date:=as.Date(date)]
# plot gcc_90
dukehw_DB_1000[,plot(date, gcc_90, col = 'green', type = 'b')]
#> NULL
mtext('Duke Forest, Hardwood', font = 2)
Download midday images
While PhenoCam sites may have many images in a given day, many simple analyses can use just the midday image when the sun is most directly overhead the canopy. Therefore, extracting a list of midday images (only one image a day) can be useful.
# obtaining midday_images for dukehw
duke_middays <- get_midday_list('dukehw')
# see the first few rows
head(duke_middays)
#> [1] "http://phenocam.nau.edu/data/archive/dukehw/2013/05/dukehw_2013_05_31_150331.jpg"
#> [2] "http://phenocam.nau.edu/data/archive/dukehw/2013/06/dukehw_2013_06_01_120111.jpg"
#> [3] "http://phenocam.nau.edu/data/archive/dukehw/2013/06/dukehw_2013_06_02_120109.jpg"
#> [4] "http://phenocam.nau.edu/data/archive/dukehw/2013/06/dukehw_2013_06_03_120110.jpg"
#> [5] "http://phenocam.nau.edu/data/archive/dukehw/2013/06/dukehw_2013_06_04_120119.jpg"
#> [6] "http://phenocam.nau.edu/data/archive/dukehw/2013/06/dukehw_2013_06_05_120110.jpg"
Now we have a list of all the midday images from this Phenocam. Let's download them and plot
# download a file
destfile <- tempfile(fileext = '.jpg')
# download only the first available file
# modify the `[1]` to download other images
download.file(duke_middays[1], destfile = destfile, mode = 'wb')
# plot the image
img <- try(readJPEG(destfile))
if(class(img)!='try-error'){
par(mar= c(0,0,0,0))
plot(0:1,0:1, type='n', axes= FALSE, xlab= '', ylab = '')
rasterImage(img, 0, 0, 1, 1)
}

Download midday images for a given time range
Now we can access all the midday images and download them one at a time. However, we frequently want all the images within a specific time range of interest. We'll learn how to do that next.
# open a temporary directory
tmp_dir <- tempdir()
# download a subset. Example dukehw 2017
download_midday_images(site = 'dukehw', # which site
y = 2017, # which year(s)
months = 1:12, # which month(s)
days = 15, # which days on month(s)
download_dir = tmp_dir) # where on your computer
# list of downloaded files
duke_middays_path <- dir(tmp_dir, pattern = 'dukehw*', full.names = TRUE)
head(duke_middays_path)
We can demonstrate the seasonality of Duke forest observed from the camera. (Note this code may take a while to run through the loop).
n <- length(duke_middays_path)
par(mar= c(0,0,0,0), mfrow=c(4,3), oma=c(0,0,3,0))
for(i in 1:n){
img <- readJPEG(duke_middays_path[i])
plot(0:1,0:1, type='n', axes= FALSE, xlab= '', ylab = '')
rasterImage(img, 0, 0, 1, 1)
mtext(month.name[i], line = -2)
}
mtext('Seasonal variation of forest at Duke Hardwood Forest', font = 2, outer = TRUE)

The goal of this section was to show how to download a limited number of midday images from the PhenoCam server. However, more extensive datasets should be downloaded from the .
The most recent release of the phenocamapi R package is available on GitHub: .
Get Lesson Code
Detecting Foggy Images using the hazer Package
Last Updated: Nov 23, 2020
In this tutorial, you will learn how to
- perform basic image processing and
- estimate image haziness as an indication of fog, cloud or other natural or artificial factors using the
hazerR package.
Read & Plot Image
We will use several packages in this tutorial. All are available from CRAN.
# load packages
library(hazer)
library(jpeg)
library(data.table)
Before we start the image processing steps, let's read in and plot an image. This image is an example image that comes with the hazer package.
# read the path to the example image
jpeg_file <- system.file(package = 'hazer', 'pointreyes.jpg')
# read the image as an array
rgb_array <- jpeg::readJPEG(jpeg_file)
# plot the RGB array on the active device panel
# first set the margin in this order:(bottom, left, top, right)
par(mar=c(0,0,3,0))
plotRGBArray(rgb_array, bty = 'n', main = 'Point Reyes National Seashore')

When we work with images, all data we work with is generally on the scale of each individual pixel in the image. Therefore, for large images we will be working with large matrices that hold the value for each pixel. Keep this in mind before opening some of the matrices we'll be creating this tutorial as it can take a while for them to load.
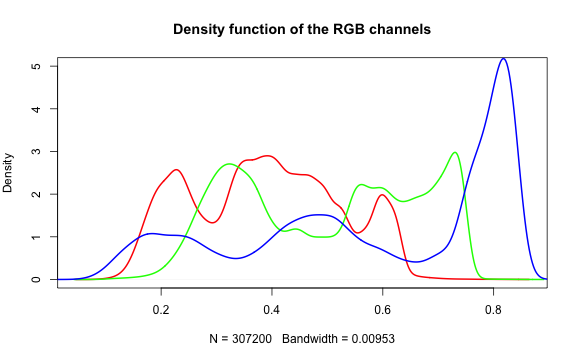
Histogram of RGB channels
A histogram of the colors can be useful to understanding what our image is made
up of. Using the density() function from the base stats package, we can extract
density distribution of each color channel.
# color channels can be extracted from the matrix
red_vector <- rgb_array[,,1]
green_vector <- rgb_array[,,2]
blue_vector <- rgb_array[,,3]
# plotting
par(mar=c(5,4,4,2))
plot(density(red_vector), col = 'red', lwd = 2,
main = 'Density function of the RGB channels', ylim = c(0,5))
lines(density(green_vector), col = 'green', lwd = 2)
lines(density(blue_vector), col = 'blue', lwd = 2)
In hazer we can also extract three basic elements of an RGB image :
- Brightness
- Darkness
- Contrast
Brightness
The brightness matrix comes from the maximum value of the R, G, or B channel. We
can extract and show the brightness matrix using the getBrightness() function.
# extracting the brightness matrix
brightness_mat <- getBrightness(rgb_array)
# unlike the RGB array which has 3 dimensions, the brightness matrix has only two
# dimensions and can be shown as a grayscale image,
# we can do this using the same plotRGBArray function
par(mar=c(0,0,3,0))
plotRGBArray(brightness_mat, bty = 'n', main = 'Brightness matrix')

Here the grayscale is used to show the value of each pixel's maximum brightness of the R, G or B color channel.
To extract a single brightness value for the image, depending on our needs we can perform some statistics or we can just use the mean of this matrix.
# the main quantiles
quantile(brightness_mat)
#> 0% 25% 50% 75% 100%
#> 0.09019608 0.43529412 0.62745098 0.80000000 0.91764706
# create histogram
par(mar=c(5,4,4,2))
hist(brightness_mat)
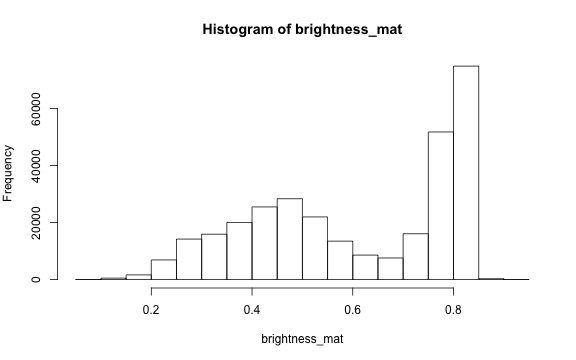
Why are we getting so many images up in the high range of the brightness? Where does this correlate to on the RGB image?
Darkness
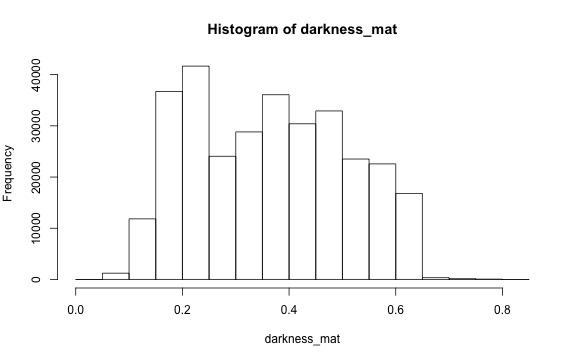
Darkness is determined by the minimum of the R, G or B color channel.
Similarly, we can extract and show the darkness matrix using the getDarkness() function.
# extracting the darkness matrix
darkness_mat <- getDarkness(rgb_array)
# the darkness matrix has also two dimensions and can be shown as a grayscale image
par(mar=c(0,0,3,0))
plotRGBArray(darkness_mat, bty = 'n', main = 'Darkness matrix')
# main quantiles
quantile(darkness_mat)
#> 0% 25% 50% 75% 100%
#> 0.03529412 0.23137255 0.36470588 0.47843137 0.83529412
# histogram
par(mar=c(5,4,4,2))
hist(darkness_mat)

Contrast
The contrast of an image is the difference between the darkness and brightness of the image. The contrast matrix is calculated by difference between the darkness and brightness matrices.
The contrast of the image can quickly be extracted using the getContrast() function.
# extracting the contrast matrix
contrast_mat <- getContrast(rgb_array)
# the contrast matrix has also 2D and can be shown as a grayscale image
par(mar=c(0,0,3,0))
plotRGBArray(contrast_mat, bty = 'n', main = 'Contrast matrix')
# main quantiles
quantile(contrast_mat)
#> 0% 25% 50% 75% 100%
#> 0.0000000 0.1450980 0.2470588 0.3333333 0.4509804
# histogram
par(mar=c(5,4,4,2))
hist(contrast_mat)

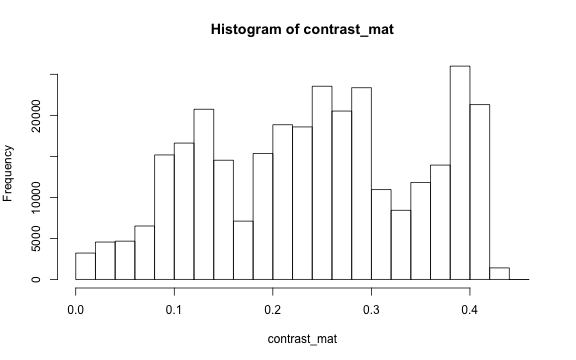
Image fogginess & haziness
Haziness of an image can be estimated using the getHazeFactor() function. This
function is based on the method described in
.
The technique was originally developed to for "detecting foggy images and
estimating the haze degree factor" for a wide range of outdoor conditions.
The function returns a vector of two numeric values:
- haze as the haze degree and
- A0 as the global atmospheric light, as it is explained in the original paper.
The PhenoCam standards classify any image with the haze degree greater than 0.4 as a significantly foggy image.
# extracting the haze matrix
haze_degree <- getHazeFactor(rgb_array)
print(haze_degree)
#> $haze
#> [1] 0.2251633
#>
#> $A0
#> [1] 0.7105258
Here we have the haze values for our image. Note that the values might be slightly different due to rounding errors on different platforms.
Process sets of images
We can use for loops or the lapply functions to extract the haze values for
a stack of images.
You can download the related datasets from .
Download and extract the zip file to be used as input data for the following step.
# to download via R
dir.create('data')
#> Warning in dir.create("data"): 'data' already exists
destfile = 'data/pointreyes.zip'
download.file(destfile = destfile, mode = 'wb', url = 'http://bit.ly/2F8w2Ia')
unzip(destfile, exdir = 'data')
# set up the input image directory
#pointreyes_dir <- '/path/to/image/directory/'
pointreyes_dir <- 'data/pointreyes/'
# get a list of all .jpg files in the directory
pointreyes_images <- dir(path = pointreyes_dir,
pattern = '*.jpg',
ignore.case = TRUE,
full.names = TRUE)
Now we can use a for loop to process all of the images to get the haze and A0 values.
(Note, this loop may take a while to process.)
# number of images
n <- length(pointreyes_images)
# create an empty matrix to fill with haze and A0 values
haze_mat <- data.table()
# the process takes a bit, a progress bar lets us know it is working.
pb <- txtProgressBar(0, n, style = 3)
#>
|
| | 0%
for(i in 1:n) {
image_path <- pointreyes_images[i]
img <- jpeg::readJPEG(image_path)
haze <- getHazeFactor(img)
haze_mat <- rbind(haze_mat,
data.table(file = image_path,
haze = haze[1],
A0 = haze[2]))
setTxtProgressBar(pb, i)
}
#>
|
|= | 1%
|
|== | 3%
|
|=== | 4%
|
|===== | 6%
|
|====== | 7%
|
|======= | 8%
|
|======== | 10%
|
|========= | 11%
|
|========== | 13%
|
|============ | 14%
|
|============= | 15%
|
|============== | 17%
|
|=============== | 18%
|
|================ | 20%
|
|================= | 21%
|
|================== | 23%
|
|==================== | 24%
|
|===================== | 25%
|
|====================== | 27%
|
|======================= | 28%
|
|======================== | 30%
|
|========================= | 31%
|
|=========================== | 32%
|
|============================ | 34%
|
|============================= | 35%
|
|============================== | 37%
|
|=============================== | 38%
|
|================================ | 39%
|
|================================= | 41%
|
|=================================== | 42%
|
|==================================== | 44%
|
|===================================== | 45%
|
|====================================== | 46%
|
|======================================= | 48%
|
|======================================== | 49%
|
|========================================== | 51%
|
|=========================================== | 52%
|
|============================================ | 54%
|
|============================================= | 55%
|
|============================================== | 56%
|
|=============================================== | 58%
|
|================================================= | 59%
|
|================================================== | 61%
|
|=================================================== | 62%
|
|==================================================== | 63%
|
|===================================================== | 65%
|
|====================================================== | 66%
|
|======================================================= | 68%
|
|========================================================= | 69%
|
|========================================================== | 70%
|
|=========================================================== | 72%
|
|============================================================ | 73%
|
|============================================================= | 75%
|
|============================================================== | 76%
|
|================================================================ | 77%
|
|================================================================= | 79%
|
|================================================================== | 80%
|
|=================================================================== | 82%
|
|==================================================================== | 83%
|
|===================================================================== | 85%
|
|====================================================================== | 86%
|
|======================================================================== | 87%
|
|========================================================================= | 89%
|
|========================================================================== | 90%
|
|=========================================================================== | 92%
|
|============================================================================ | 93%
|
|============================================================================= | 94%
|
|=============================================================================== | 96%
|
|================================================================================ | 97%
|
|================================================================================= | 99%
|
|==================================================================================| 100%
Now we have a matrix with haze and A0 values for all our images. Let's compare top five images with low and high haze values.
haze_mat[,haze:=unlist(haze)]
top10_high_haze <- haze_mat[order(haze), file][1:5]
top10_low_haze <- haze_mat[order(-haze), file][1:5]
par(mar= c(0,0,0,0), mfrow=c(5,2), oma=c(0,0,3,0))
for(i in 1:5){
img <- readJPEG(top10_low_haze[i])
plot(0:1,0:1, type='n', axes= FALSE, xlab= '', ylab = '')
rasterImage(img, 0, 0, 1, 1)
img <- readJPEG(top10_high_haze[i])
plot(0:1,0:1, type='n', axes= FALSE, xlab= '', ylab = '')
rasterImage(img, 0, 0, 1, 1)
}
mtext('Separating out foggy images of Point Reyes, CA', font = 2, outer = TRUE)
![]()
Let's classify those into hazy and non-hazy as per the PhenoCam standard of 0.4.
# classify image as hazy: T/F
haze_mat[haze>0.4,foggy:=TRUE]
haze_mat[haze<=0.4,foggy:=FALSE]
head(haze_mat)
#> file haze A0 foggy
#> 1: data/pointreyes//pointreyes_2017_01_01_120056.jpg 0.2249810 0.6970257 FALSE
#> 2: data/pointreyes//pointreyes_2017_01_06_120210.jpg 0.2339372 0.6826148 FALSE
#> 3: data/pointreyes//pointreyes_2017_01_16_120105.jpg 0.2312940 0.7009978 FALSE
#> 4: data/pointreyes//pointreyes_2017_01_21_120105.jpg 0.4536108 0.6209055 TRUE
#> 5: data/pointreyes//pointreyes_2017_01_26_120106.jpg 0.2297961 0.6813884 FALSE
#> 6: data/pointreyes//pointreyes_2017_01_31_120125.jpg 0.4206842 0.6315728 TRUE
Now we can save all the foggy images to a new folder that will retain the foggy images but keep them separate from the non-foggy ones that we want to analyze.
# identify directory to move the foggy images to
foggy_dir <- paste0(pointreyes_dir, 'foggy')
clear_dir <- paste0(pointreyes_dir, 'clear')
# if a new directory, create new directory at this file path
dir.create(foggy_dir, showWarnings = FALSE)
dir.create(clear_dir, showWarnings = FALSE)
# copy the files to the new directories
file.copy(haze_mat[foggy==TRUE,file], to = foggy_dir)
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [15] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [29] FALSE FALSE
file.copy(haze_mat[foggy==FALSE,file], to = clear_dir)
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [15] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
#> [29] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
Now that we have our images separated, we can get the full list of haze values only for those images that are not classified as "foggy".
# this is an alternative approach instead of a for loop
# loading all the images as a list of arrays
pointreyes_clear_images <- dir(path = clear_dir,
pattern = '*.jpg',
ignore.case = TRUE,
full.names = TRUE)
img_list <- lapply(pointreyes_clear_images, FUN = jpeg::readJPEG)
# getting the haze value for the list
# patience - this takes a bit of time
haze_list <- t(sapply(img_list, FUN = getHazeFactor))
# view first few entries
head(haze_list)
#> haze A0
#> [1,] 0.224981 0.6970257
#> [2,] 0.2339372 0.6826148
#> [3,] 0.231294 0.7009978
#> [4,] 0.2297961 0.6813884
#> [5,] 0.2152078 0.6949932
#> [6,] 0.345584 0.6789334
We can then use these values for further analyses and data correction.
The hazer R package is developed and maintained by . The most recent release is available from .
Get Lesson Code
Extracting Timeseries from Images using the xROI R Package
Last Updated: Jun 10, 2024